
✅ 쿼리 최적화의 필요성
쿼리 최적화가 필요하다고 생각한 API는 두 가지이다.
1️⃣ 답변 목록 조회 API
1. 답변 리스트 페이징해서 조회
User answerAuthor = userRepository.findById(answer.getUserId())
.orElseThrow(() -> UserNotFoundException.EXCEPTION);SELECT
answer.answer_id,
answer.content,
answer.created_at,
answer.like_count,
answer.question_id,
answer.url,
answer.user_id,
answer.visibility
FROM
answer
JOIN
question ON question.question_id = answer.question_id
WHERE
question.category_id = ?
AND question.question_status = ?
AND answer.created_at < ?
ORDER BY
answer.created_at DESC
LIMIT ?, ?;
1번에서 받아온 Answer의 리스트에 대해 반복문을 돌며 다음의 쿼리를 실행
2. 답변을 작성한 사용자 정보 조회
User answerAuthor = userRepository.findById(answer.getUserId())
.orElseThrow(() -> UserNotFoundException.EXCEPTION);SELECT
users.user_id,
users.description,
users.email,
users.is_usable,
users.nickname,
users.password,
users.profile_image,
users.user_role
FROM
users
WHERE
users.user_id = ?;
3. API 요청한 사용자가 해당 답변에 좋아요를 눌렀는지 확인하는 조회
// 특정 사용자가 특정 글에 좋아요를 눌렀는지
return likeRepository
.existsByUserEntityIdAndTargetIdAndTargetType(currentUserId, targetId, targetType);SELECT
likes.id
FROM
likes
WHERE
likes.user_id = ?
AND likes.target_id = ?
AND likes.target_type = ?
LIMIT ?;
4. API 요청한 사용자가 답변 작성자를 팔로우 했는지를 확인하는 조회
// 해당 사용자가 특정 작성자(작성자 ID)를 팔로우 했는지 확인
return followRepository.findByFollowerIdAndFolloweeId(currentUserId, authorId)
.isPresent();SELECT
follows.followee_id,
follows.follower_id,
follows.created_at
FROM
follows
WHERE
follows.follower_id = ?
AND follows.followee_id = ?;
5. 해당 답변의 댓글 수를 조회
int commentCount =
answerCommentRepository.countParentCommentByAnswerId(answer.getAnswerId().getValue());SELECT
COUNT(answer_comment.answer_comment_id)
FROM
answer_comment
WHERE
answer_comment.answer_id = ?;
✔️ 쿼리 실행 횟수
답변이 한개일 경우 5번, 답변이 하나씩 늘어날 때마다 4번씩 쿼리가 증가한다.
페이징 크기의 기본값이 10개인데 10개의 답변이라면 총 41번의 쿼리가 발생한다.
2️⃣ 답변 상세 조회 API
[답변 정보]
1. 해당 답변 조회
// 답변 정보 받아오기
Answer answer = answerRepository.findById(request.answerId())
.orElseThrow(() -> AnswerNotFoundException.EXCEPTION);SELECT
answer.answer_id,
answer.content,
answer.created_at,
answer.like_count,
answer.question_id,
answer.url,
answer.user_id,
answer.visibility
FROM
answer
JOIN
question ON question.question_id = answer.question_id
WHERE
question.category_id = ?
AND question.question_status = ?
AND answer.created_at < ?
ORDER BY
answer.created_at DESC
LIMIT ?, ?;
2. 답변을 작성한 사용자 정보 조회
User answerAuthor = userRepository.findById(answer.getUserId())
.orElseThrow(() -> UserNotFoundException.EXCEPTION);SELECT
users.user_id,
users.description,
users.email,
users.is_usable,
users.nickname,
users.password,
users.profile_image,
users.user_role
FROM
users
WHERE
users.user_id = ?;
3. API 요청한 사용자가 해당 답변에 좋아요를 눌렀는지 확인하는 조회
// 특정 사용자가 특정 글에 좋아요를 눌렀는지
return likeRepository
.existsByUserEntityIdAndTargetIdAndTargetType(currentUserId, targetId, targetType);SELECT
likes.id
FROM
likes
WHERE
likes.user_id = ?
AND likes.target_id = ?
AND likes.target_type = ?
LIMIT ?;
4. API 요청한 사용자가 답변 작성자를 팔로우 했는지를 확인하는 조회
// 해당 사용자가 특정 작성자(작성자 ID)를 팔로우 했는지 확인
return followRepository.findByFollowerIdAndFolloweeId(currentUserId, authorId)
.isPresent();SELECT
follows.followee_id,
follows.follower_id,
follows.created_at
FROM
follows
WHERE
follows.follower_id = ?
AND follows.followee_id = ?;
[답변의 댓글 정보]
5. 최상위 부모 댓글들 페이징 조회
// 해당 Answer에 대한 최상위 부모 댓글들 페이징으로 가져오기
List<AnswerComment> parentComments =
answerCommentRepository.findParentCommentsByAnswerIdWithCursor(request.answerId(), request.cursor(), request.size());SELECT
answer_comment.answer_comment_id,
answer_comment.answer_id,
answer_comment.content,
answer_comment.created_at,
answer_comment.depth,
answer_comment.like_count,
answer_comment.parent_comment_id,
answer_comment.user_id
FROM
answer_comment
WHERE
answer_comment.answer_id = ?
AND answer_comment.parent_comment_id IS NULL
AND answer_comment.created_at < ?
ORDER BY
answer_comment.created_at DESC
LIMIT ?, ?;
최상위 부모댓글들을 가지고 다음의 쿼리를 반복적으로 실행(최상위 부모 댓글 갯수만큼)
6. 댓글 작성자 정보 조회
User commentAuthor = userRepository.findById(UserId.of(parent.getUserId().getValue()))
.orElseThrow(() -> UserNotFoundException.EXCEPTION);SELECT
users.user_id,
users.description,
users.email,
users.is_usable,
users.nickname,
users.password,
users.profile_image,
users.user_role
FROM
users
WHERE
users.user_id = ?;
7. API 요청한 사용자가 해당 댓글에 좋아요를 눌렀는지 확인하는 조회
boolean isLike = buildIsLike(reqUserId, parent.getParentAnswerCommentId().getValue(), ANSWER_COMMENT);SELECT
likes.id
FROM
likes
WHERE
likes.user_id = ?
AND likes.target_id IS NULL
AND likes.target_type = ?
LIMIT ?;
8. API 요청한 사용자가 댓글 작성자를 팔로우 했는지를 확인하는 조회
boolean isFollowing = buildIsFollowing(reqUserId, commentAuthor.getId().getValue());SELECT
follows.followee_id,
follows.follower_id,
follows.created_at
FROM
follows
WHERE
follows.follower_id = ?
AND follows.followee_id = ?;
9. 조회해온 부모댓글들의 Id로 자식 댓글 조회
// 부모 Comment에 대한 하위 댓글 조회
List<AnswerComment> childComments =
answerCommentRepository.findChildCommentsByParentsId(parentIds);SELECT
answer_comment.answer_comment_id,
answer_comment.answer_id,
answer_comment.content,
answer_comment.created_at,
answer_comment.depth,
answer_comment.like_count,
answer_comment.parent_comment_id,
answer_comment.user_id
FROM
answer_comment
WHERE
answer_comment.parent_comment_id IN (?, ?, ?, ?, ?, ?, ?, ?, ?, ?);
9번에서 받아온 자식 댓글을 부모댓글로 설정하여 재귀적으로 더 이상 자식 댓글이 없을 때 까지 6~8번의 과정을 반복적으로 수행한다.
✔️ 쿼리 실행 횟수
답변 댓글에 대한 페이징 크기의 기본값이 10개인데 각 댓글의 대댓글이 2개씩만 있다고 가정해도 69번의 쿼리가 발생한다.
‼️ 이 두개의 API는 호출이 빈번할 수 밖에 없는 API들인데 한번의 호출로 몇십번의 쿼리가 나간다면 서비스 사용자가 조금만 많아져도 정상적으로 동작하기 힘들 것이다. 지금부터 이 API들의 쿼리들을 최적화해보도록 하겠다.
🔑 쿼리 최적화 전략
사실 무조건 조인을 해서 쿼리를 줄이는 것이 성능에 도움이 되는 것은 아니다.
조인이 복잡해지면 쿼리 자체의 실행시간이 늘어나고 조인 결과에 불필요한 데이터가 포함될 수도 있기 때문에 오히려 성능에 악영향을 미칠 수 있다.
또한 아무리 성능이 좋다고 해도 쿼리가 복잡해지거나 코드가 지나치게 복잡해지면 가독성이 떨어지고 유지보수가 힘들어지기 때문에 무조건 좋다고 할 수는 없다.
그렇기 때문에 그 적당한 선을 잘 찾는 것이 중요하다.
따라서 기존방식과 비교해가며 성능 테스트를 할 것이다. 그렇게 조금씩 변경해가며 최적점을 찾는 것이 최적화의 목적이다.
성능 테스트 툴은 JMeter를 사용하였다.
✅ 테스트 더미 데이터
테스트를 위해 더미데이터를 테이블 별로 약 10000개 씩 추가하였다.
User

Answer

Like

Follow
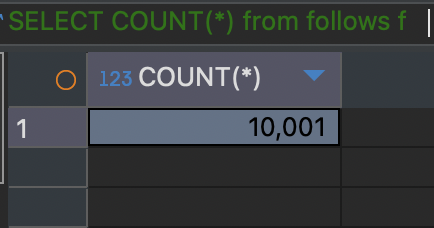
AnswerComment

✅ 답변 목록 조회 API
1️⃣ 기존 방식
☝️성능 테스트 결과
[1000건 동시요청]

API 요청당 평균 3.6초의 시간이 소요되었다.
2️⃣ 쿼리 개선
현재 방식에서 가장 큰 문제는 페이징해서 받아온 Answer를 가지고 반복문을 돌며 Answer의 갯수만큼 4번의 추가쿼리를 날린다는 것이다. Answer의 갯수가 10개만 되어도 40번의 추가 쿼리가 나간다.
// 답변 리스트 페이징해서 불러오기
List<Answer> answers = answerRepository.findAllByCategoryIdWithCursor(request.cursor(), request.size(), request.categoryId());
for (Answer answer : answers) {
/**
1. 답변 작성자 조회 쿼리
2. API 요청 사용자의 좋아요 누름 여부 조회 쿼리
3. API 요청 사용자의 팔로우 여부 조회 쿼리
4. 댓글 갯수 조회 쿼리
*/
}
🤔 이를 어떻게 개선할 수 있을까?
바로 4번의 추가 쿼리를 각 Answer에 대해서 한번씩 실행하는 것이 아니라 한번에 실행하는 것이다.
4번의 추가쿼리는 대부분 Answer의 정보를 필요로 한다.
- 답변 작성자 조회쿼리 - Answer의 작성자 ID
- API 요청 사용자의 해당 답변 좋아요 누름 여부 조회 쿼리 - Answer의 ID
- API 요청 사용자의 해당 답변 팔로우 여부 조회 쿼리 - Answer 작성자의 ID
- 댓글 갯수 조회 쿼리 - Answer의 ID
페이징 쿼리를 통해 이미 필요한 모든 Answer의 정보를 알고 있으므로 한번에 모든 정보를 조회할 수 있다.
💡 개선된 쿼리
1. 답변 리스트 페이징해서 조회 (이전과 동일)
// 답변 리스트 페이징해서 불러오기
List<Answer> answers = answerRepository
.findAllByCategoryIdWithCursor(request.cursor(), request.size(), request.categoryId());SELECT
answer.answer_id,
answer.content,
answer.created_at,
answer.like_count,
answer.question_id,
answer.url,
answer.user_id,
answer.visibility
FROM
answer
JOIN
question ON question.question_id = answer.question_id
WHERE
question.category_id = ?
AND question.question_status = ?
AND answer.created_at < ?
ORDER BY
answer.created_at DESC
LIMIT ?, ?;
2. 모든 답변 작성자 정보 조회 쿼리
// 답변 작성자 ID만 리스트로 뽑아내기
List<String> answerAuthorIds = answers.stream()
.map(answer -> answer.getUserId().getValue())
.toList();
// 작성자 정보 조회
List<User> answerAuthors = userRepository.findUsersByIds(answerAuthorIds);SELECT
users.user_id,
users.description,
users.email,
users.is_usable,
users.nickname,
users.password,
users.profile_image,
users.user_role
FROM
users
WHERE
users.user_id IN (?, ?, ?, ?, ?, ?, ?, ?, ?, ?);- 한번에 모든 작성자의 정보를 받아오도록 하였다.
3. API 사용자의 모든 답변들 좋아요 누름 여부 조회 쿼리
// Id만 리스트로 뽑아내기
List<Long> answerIds = answers.stream()
.map(answer -> answer.getAnswerId().getValue())
.toList();
// 좋아요 정보 조회
List<Like> likes = likeRepository.findByTargetIdsInAndTargetTypeAndUserId(answerIds, ANSWER, request.userId());SELECT
likes.id,
likes.target_id,
likes.target_type,
likes.user_id
FROM
likes
WHERE
likes.target_id IN (?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
AND likes.target_type = ?
AND likes.user_id = ?;- 한번에 모든 좋아요 정보를 받아오도록 하였다.
4. API 요청 사용자의 모든 답변 작성자들 팔로우 여부 조회 쿼리
// 답변 작성자 ID만 리스트로 뽑아내기
List<String> answerAuthorIds = answers.stream()
.map(answer -> answer.getUserId().getValue())
.toList();
// 팔로우 정보 조회
List<Follow> follows = followRepository.findByFollowerIdAndFolloweeIds(request.userId(), answerAuthorIds);SELECT
follows.followee_id,
follows.follower_id,
follows.created_at
FROM
follows
WHERE
follows.follower_id = ?
AND follows.followee_id IN (?, ?, ?, ?, ?, ?, ?, ?, ?, ?);
- 한번에 모든 팔로우 정보를 받아오도록 하였다.
5. 댓글 갯수 조회 쿼리
// Id만 리스트로 뽑아내기
List<Long> answerIds = answers.stream()
.map(answer -> answer.getAnswerId().getValue())
.toList();
// 댓글 갯수 조회
List<AnswerCommentCountDTO> answerCommentCounts = answerCommentRepository.countCommentsByAnswerIds(answerIds);SELECT
answer_comment.answer_id,
COUNT(answer_comment.answer_comment_id)
FROM
answer_comment
GROUP BY
answer_comment.answer_id
HAVING
answer_comment.answer_id IN (?, ?, ?, ?, ?, ?, ?, ?, ?, ?);- 댓글 갯수를 저장하는 컬럼이 없었기 때문에 별도의 DTO클래스를 정의하여 처리하였다.
이후 받아온 정보를 어플리케이션 단에서 직접 처리한다.
List<AnswerFindServiceResponse> responses = answers.stream()
.map(answer -> {
// 데이터 처리...
}).toList();
데이터 갯수가 많은 경우, 반복문을 돌리는것이 오히려 비효율적일 수도 있겠지만, 여기선 페이징을 통해서 10개의 데이터만 가져와 반복문이 10번만 실행되므로 괜찮다고 생각했다.
☝️ 쿼리 개선 결과
해당방식으로 변경한 결과
페이징 크기 10개 기준, 41번의 쿼리에서 5번의 쿼리로 감소하였다.
☝️성능 테스트 결과
[1000건 동시 요청]

평균 2초로 이전 3.6초에서 약 44% 개선되었다.
3️⃣ 전부 조인
말그대로 필요한 정보를 전부 조인해 한번의 쿼리로 가져왔다.
SELECT
answer.answer_id,
users.user_id,
users.nickname,
users.profile_image,
answer.content,
answer.created_at,
answer.like_count,
CASE
WHEN likes.id IS NOT NULL THEN 1
ELSE 0
END AS is_liked,
CASE
WHEN (follows.followee_id IS NOT NULL OR follows.follower_id IS NOT NULL) THEN 1
ELSE 0
END AS is_followed,
COUNT(answer_comment.answer_comment_id) AS comment_count
FROM
answer
JOIN
question ON question.question_id = answer.question_id
JOIN
users ON answer.user_id = users.user_id
LEFT JOIN
likes ON likes.target_id = answer.answer_id
AND likes.target_type = ?
AND likes.user_id = ?
LEFT JOIN
follows ON follows.follower_id = ?
AND follows.followee_id = users.user_id
LEFT JOIN
answer_comment ON answer_comment.answer_id = answer.answer_id
WHERE
question.category_id = ?
AND question.question_status = ?
AND answer.created_at < ?
GROUP BY
answer.answer_id
ORDER BY
answer.created_at DESC
LIMIT ?, ?;
☝️ 성능 테스트 결과
[동시 1000건 요청]

평균 11초로 오히려 처음 방식인 41번 쿼리가 나갈때보다 3배가량 증가하였다.
아무래도 쿼리자체가 복잡하고 데이터 갯수가 많다보니 그런 것 같다.
🔑 결론
2️⃣번 방식이 제일 적합하다고 생각했다.
쿼리 수도 절대적으로 줄일 수 있고 성능도 올라가며 코드나 쿼리의 복잡성도 적당한 것 같다.
📌 쿼리 횟수를 기본 페이징 기준(크기 : 10) 41번에서 5번으로 약 87% 감소하였고
응답속도는 1000건 동시요청 시 평균 3.6초에 2초로 약 44% 개선하였다.
✅ 답변 상세 조회 API
1️⃣ 기존 방식
☝️ 성능 테스트 결과
[1000건 동시요청]

평균 약 4.7초정도가 소요되었다.
2️⃣ 쿼리 개선
우선 답변 상세 조회 API에서 실행되는 쿼리를 다시한번 정리해보자.
[답변 정보]
1. 해당 답변 조회
2. 답변을 작성한 사용자 정보 조회
3. API 요청한 사용자가 해당 답변에 좋아요를 눌렀는지 확인하는 조회
4. API 요청한 사용자가 답변 작성자를 팔로우 했는지를 확인하는 조회
[댓글 정보]
5. 최상위 부모 댓글들 페이징 조회
부모댓글들을 가지고 다음의 쿼리를 반복적으로 실행(부모 댓글 갯수만큼)
6. 댓글 작성자 정보 조회
7. API요청한 사용자가 해당 댓글에 좋아요를 눌렀는지 확인하는 조회
8. API 요청한 사용자가 댓글 작성자를 팔로우 했는지를 확인하는 조회
9. 조회해온 부모댓글들의 Id로 자식 댓글 조회
자식 댓글을 부모댓글로 설정하여 재귀적으로 더이상 자식 댓글이 없을 때 까지 6~8번까지의 과정을 수행한다.
답변정보에 관한 쿼리는 앞선 답변목록 조회 API와 흡사한데 앞서 조인을 하면 오히려 성능이 나빠진다는 것을 확인했으니 넘어가자.
제일 문제가 되는 것은 댓글관련 부분이다.
부모댓글들을 먼저조회하고 이후에 자식댓글을 조회한다.
그리고 해당 정보들을 가지고 재귀적으로 댓글 관련 정보에 대한 추가쿼리를 날린다.
여기서 말하는 댓글 관련 정보는 6번부터 8번 쿼리를 통해 가져오는 댓글 작성자, 좋아요, 팔로우 정보를 의미한다.
재귀적으로 쿼리를 날리다보니 대댓글이 많아질수록 쿼리 수가 늘어나게된다.
🤔 이를 어떻게 개선할 수 있을까?
댓글의 계층이 무한으로 설정되어 있기 때문에 어쩔 수 없이 재귀적으로 댓글을 가져와야 하지만 그렇다고 해서 댓글 관련 정보까지 재귀적으로 가져올 필요는 없다. 먼저 댓글만 재귀적으로 조회해 모든 댓글 정보를 가져오고 그 정보를 기반으로 댓글 관련 정보를 한번에 가져오면 된다.
💡 댓글 처리 방식 개선
1. 최상위 부모 댓글들 페이징 조회 (이전과 동일)
// 페이징으로 최상위 부모 댓글 가져오기
List<AnswerComment> parentComments = answerCommentRepository.findParentCommentsByAnswerIdWithCursor(request.answerId(), request.cursor(), request.size());SELECT
answer_comment.answer_comment_id,
answer_comment.answer_id,
answer_comment.content,
answer_comment.created_at,
answer_comment.depth,
answer_comment.like_count,
answer_comment.parent_comment_id,
answer_comment.user_id
FROM
answer_comment
WHERE
answer_comment.answer_id = ?
AND answer_comment.parent_comment_id IS NULL
AND answer_comment.created_at < ?
ORDER BY
answer_comment.created_at DESC
LIMIT ?, ?;
2. 조회해온 부모 댓글들의 Id로 부모댓글들에 대한 자식 댓글 조회
// 부모 댓글에 대한 자식 댓글 조회
List<AnswerComment> childComments =
answerCommentRepository.findChildCommentsByParentsId(parentIds);SELECT
answer_comment.answer_comment_id,
answer_comment.answer_id,
answer_comment.content,
answer_comment.created_at,
answer_comment.depth,
answer_comment.like_count,
answer_comment.parent_comment_id,
answer_comment.user_id
FROM
answer_comment
WHERE
answer_comment.parent_comment_id IN (?, ?, ?, ?, ?, ?, ?, ?, ?, ?);
이 과정을 자식 댓글을 부모댓글로 설정하여 재귀적으로 더 이상 자식 댓글이 없을 때까지 반복한다.
private void buildAnswerCommentDTOList(List<AnswerComment> parentComments, String reqUserId, List<AnswerCommentFindServiceResponse> commentDTOs) {
// ..로직 생략
// 부모 댓글에 대한 자식 댓글 조회
List<AnswerComment> childComments = answerCommentRepository.findChildCommentsByParentsId(parentIds);
// 자식 댓글이 없으면 종료
if(childCommnets.isEmpty()) return;
// 재귀적으로 호출
buildAnswerCommentDTOList(childComments, reqUserId, commentDTOs);
}- 이러면 최상위 부모댓글의 모든 대댓글을 가져오게 된다.
필요한 모든 댓글들을 가져왔으므로 해당 정보를 기반으로 댓글 관련 정보를 한번에 가져온다.
3. 모든 댓글의 작성자 조회
// 모든 댓글 작성자 조회
List<User> commentAuthors = userRepository.findUsersByIds(commentAuthorIds);SELECT
users.user_id,
users.description,
users.email,
users.is_usable,
users.nickname,
users.password,
users.profile_image,
users.user_role
FROM
users
WHERE
users.user_id IN (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?);
4. API 요청한 사용자가 모든 댓글들에 좋아요를 눌렀는지 조회
// 모든 좋아요 정보 조회
List<Like> likes =
likeRepository.findByTargetIdsInAndTargetTypeAndUserId(commentIds, ANSWER_COMMENT, request.userId());SELECT
likes.id,
likes.target_id,
likes.target_type,
likes.user_id
FROM
likes
WHERE
likes.target_id IN (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
AND likes.target_type = ?
AND likes.user_id = ?;
5. API 요청한 사용자가 모든 댓글 작성자들에게 팔로우를 했는지 조회
// 모든 팔로우 정보 조회
List<Follow> follows =
followRepository.findByFollowerIdAndFolloweeIds(request.userId(), commentAuthorIds);SELECT
follows.followee_id,
follows.follower_id,
follows.created_at
FROM
follows
WHERE
follows.follower_id = ?
AND follows.followee_id IN (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?);
받아온 정보들을 가지고 반복문을 통해 처리한다.
rawAnswerCommentDTOs.forEach(
answerCommentDTO -> {
// 데이터 셋팅
}
);데이터 갯수가 많은 경우, 반복문을 돌리는것이 오히려 비효율적일 수도 있겠지만, 댓글 역시도 답변과 마찬가지로 페이징을 통해서 10개의 데이터만 가져와 반복문이 10번만 실행되므로 괜찮다고 생각했다.
☝️ 쿼리 개선 결과
해당 방식으로 변경한 결과
페이징 크기 10, 각 댓글에 대댓글이 2개씩 존재하는 상황 기준 쿼리횟수를 69번에서 11번으로 감소시켰다.
☝️ 성능 테스트 결과
[1000건 동시 요청]

기존 4.7초에서 1.6초로 약 66% 성능이 개선되었다.
🔑 결론
📌 쿼리 횟수를 기본 페이징(크기 : 10), 대댓글 2개 기준 69번에서 11번으로 약 84% 감소하였고
응답속도는 1000건 동시요청 기준 평균 3.6초에 2초로 약 66% 개선되었다.
- 코드가 복잡해지는 트레이드 오프가 있긴 하지만 이정도의 쿼리 횟수 및 성능차이면 충분히 감안할만한 부분이라고 생각했다.
'데브코스 > 실습 & 프로젝트' 카테고리의 다른 글
| [최종 프로젝트] 오늘의 질문 조회 캐싱하기 (0) | 2024.12.31 |
|---|---|
| [최종 프로젝트] 좋아요 API 동시성 이슈 해결 - 2-2. Answer 테이블 데이터 정합성 문제 해결: 분산 락(Redisson 적용) (1) | 2024.12.31 |
| [최종 프로젝트] 좋아요 API 동시성 이슈 해결 - 2-1. Answer 테이블 데이터 정합성 문제 해결: 비관적 락(@Lock) 적용 (0) | 2024.12.31 |
| [최종 프로젝트] 좋아요 API 동시성 이슈 해결 - 1. Like 테이블 데이터 정합성 문제 (0) | 2024.12.31 |
| [최종 프로젝트] 좋아요 API 동시성 이슈 해결 - 0. 배경 설명 (1) | 2024.12.31 |