
Intro.
지금까지 Github API 사용법, ChatGPT API 사용법을 알아봤으니 둘을 사용해서 서비스를 개발해볼 시간이다.
Fast API를 통해 간단히 API를 개발하고 PostMan으로 테스트 해보겠다.
시작에 앞서 구조를 한번 그림으로 정리해봤다
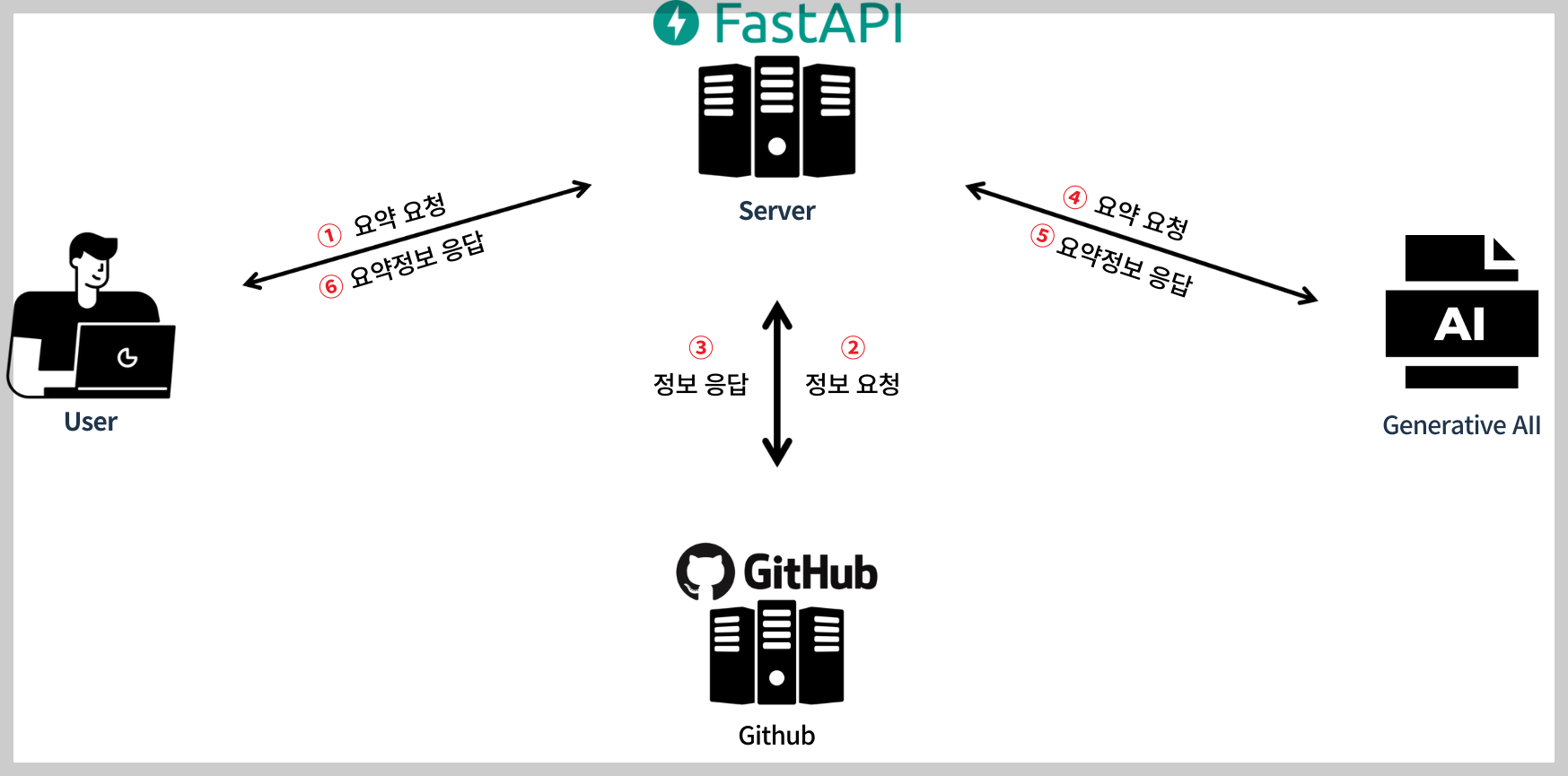
Github Repository의 정보를 가져오기
리포지토리의 어떤 정보를 받아와야 GPT가 잘 요약을 할 수 있을지 고민을 했었다.
1.Readme.md
사실 최고는 잘 정리된 readme.md 파일을 읽어오는 것이다. 하지만 모든 개발자가 readme를 제대로 정리 안해놓을 수도 있고 애초에 이 요약서비스를 사용한다는 것 자체가 그러한 정리에 익숙치 않거나 귀찮아 하는 사람들일 가능성이 크기 때문에 readme.md는 후보가 될 수는 있지만 그것 만으로는 부족하다.
2. 코드
이것도 확실한 방법이긴하다. gpt가 코드를 읽는다면 너무나도 정확하게 프로젝트에 대해 요약해줄 것이다. 하지만 한 프로젝트의 코드의 길이는 상상을 초월할 정도로 길다. GPT API를 포함한 모든 LLM API들은 입력 최대 토큰 수 제한이 있기 때문에 모든 코드를 받아오는 것을 무리이다.
3. 디렉토리명 및 파일명
사실 코드까지 안가더라도 디렉토리와 파일 명을 통해서도 충분히 프로젝트의 주제 및 사용된 언어, 프레임워크가 유추가 가능하다. 또한 디렉토리와 파일 명을 이용한다면 입력 토큰 수도 상당히 줄어들 것이다.
일단 디렉토리명, 파일명, Readme.md 이 세가지 정보를 사용하기로 결정했다.(결과에 따라 변경 가능)
코드
자 이제 개발한 코드를 살펴보자.
import aiohttp
import asyncio
import base64
from dotenv import load_dotenv
import os
## Github Repository의 readme, 디렉토리명, 파일명을 불러온다.
load_dotenv()
# GitHub API 설정
TOKEN = os.getenv('GIT_TOKEN')
HEADERS = {'Authorization': f'token {TOKEN}'}
API_BASE_URL = 'https://api.github.com'
async def get_repo_contents(session, owner, repo, path=''):
# GitHub repository 내의 파일 및 디렉토리 목록을 비동기적으로 가져옴
url = f'{API_BASE_URL}/repos/{owner}/{repo}/contents/{path}'
async with session.get(url, headers=HEADERS) as response:
return await response.json()
async def get_readme_content(session, owner, repo, path):
# README.md 파일의 내용을 비동기적으로 가져옴
contents = await get_repo_contents(session, owner, repo, path)
if 'content' in contents:
# Base64로 인코딩된 문자열을 디코딩
decoded_content = base64.b64decode(contents['content']).decode('utf-8')
return decoded_content
return None
async def explore_repo(session, owner, repo, path='', result=None):
if result is None:
result = {'directories': [], 'files': [], 'readme': ''}
contents = await get_repo_contents(session, owner, repo, path)
tasks = []
for content in contents:
if content['type'] == 'file':
if content['name'].lower() == 'readme.md':
readme_content = await get_readme_content(session, owner, repo, content['path'])
result['readme'] = readme_content
else:
result['files'].append(content['name'])
elif content['type'] == 'dir':
result['directories'].append(content['name'])
tasks.append(explore_repo(session, owner, repo, content['path'], result))
# 모든 태스크를 병렬로 실행
await asyncio.gather(*tasks)
return result
async def run(owner, repo):
async with aiohttp.ClientSession() as session:
result = await explore_repo(session, owner, repo)
# print(result)
return result
이 코드의 핵심은 aiohttp, asyncio를 통해 비동기적으로 api요청을 처리했다는 점이다.
디렉토리명, 파일명을 읽어오는 과정은 다음과 같이 재귀적으로 일어난다.

이러한 작업을 동기적으로 실행한다면 레포지토리의 파일이 조금만 많아져도 상당한 지연이 발생할 것이다.
그렇기 때문에 비동기적으로 처리했다.
결과화면
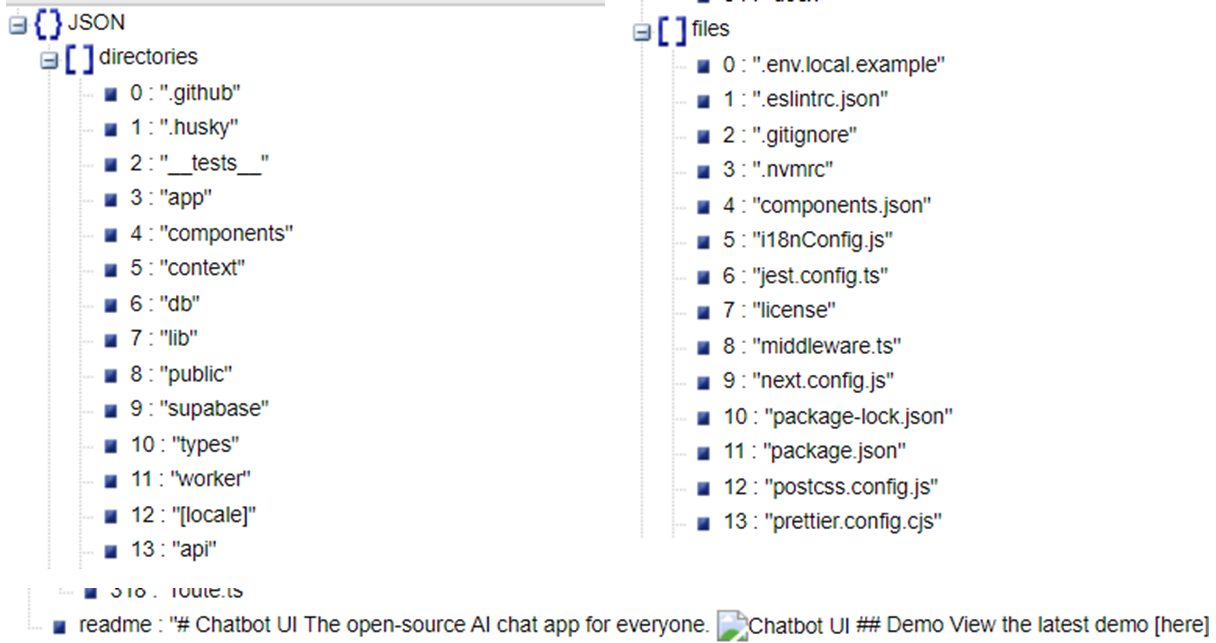
정상적으로 잘 불러온 것을 알 수 있다.
ChatGPT API를 통해 요약하기
가져온 레포지토리 정보를 기반으로 GPT API를 통해 요약하는 코드를 작성해보았다.
from dotenv import load_dotenv
import os
from openai import OpenAI
from read_repos import run
from calculate_bills import calculate
load_dotenv()
# openai_api_key = os.getenv('OPENAI_API_KEY')
client = OpenAI()
async def gpt_summarize(repos_url, role, leader, extra_info= None):
result = await setParamter(repos_url)
directories = ','.join(result['directories'])
files = ','.join(result['files'])
readme = result['readme']
period = '20231123-20240215'
request_messages = [
{"role": "system", "content": '''너는 프로젝트를 요약해주는 AI야.
요약 내용에는 세가지 정보가 포함돼.
1. project_info: 프로젝트 주제, 사용 언어및 프레임워크, 내가 맡은 역할
2. period: 프로젝트 기간
3. core_function: 프로젝트의 상세한 핵심기능(맡은 역할과 엮어서)
이 내용들은 이력서에 들어갈 것이야.
1번과 3번은 하나의 문장으로 주고 2번은 그냥 기간만'''},
{"role": "user", "content": "디렉토리명은 " + directories},
{"role": "user", "content": "파일명은 " + files},
{"role": "user", "content": "readme는 " + readme},
{"role": "user", "content": "역할은 " + role},
{"role": "user", "content": "리더여부는 " + str(leader)},
{"role": "user", "content": "기간은 " + period}
]
if extra_info is not None:
request_messages.append({"role": "user", "content": "추가적인 정보는 " + str(extra_info)})
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
response_format={ "type": "json_object" },
#프로젝트의핵심기능, 소개(언어 및 프레임워크)
messages=request_messages,
temperature=1
)
completion.choices[0].message.content
print(completion.usage)
print(calculate(completion.usage.completion_tokens, completion.usage.prompt_tokens))
return completion.choices[0].message.content
async def setParamter(repos_url):
parts = repos_url.split('/')
user_name = parts[3]
repo_name = parts[4]
result = await run(user_name, repo_name)
return result앞서 작성했던 깃허브 레포지토리 관련 코드를 import해 사용했다.
다음은 프롬프트에 대한 부분이다.
result = await setParamter(repos_url)
directories = ','.join(result['directories'])
files = ','.join(result['files'])
readme = result['readme']
period = '20231123-20240215'
request_messages = [
{"role": "system", "content": '''너는 프로젝트를 요약해주는 AI야.
요약 내용에는 세가지 정보가 포함돼.
1. project_info: 프로젝트 주제, 사용 언어및 프레임워크, 내가 맡은 역할
2. period: 프로젝트 기간
3. core_function: 프로젝트의 상세한 핵심기능(맡은 역할과 엮어서)
이 내용들은 이력서에 들어갈 것이야.
1번과 3번은 하나의 문장으로 주고 2번은 그냥 기간만'''},
{"role": "user", "content": "디렉토리명은 " + directories},
{"role": "user", "content": "파일명은 " + files},
{"role": "user", "content": "readme는 " + readme},
{"role": "user", "content": "역할은 " + role},
{"role": "user", "content": "리더여부는 " + str(leader)},
{"role": "user", "content": "기간은 " + period}
]
if extra_info is not None:
request_messages.append({"role": "user", "content": "추가적인 정보는 " + str(extra_info)})
readme, 디렉토리명, 파일명외에도 사용자가 UI에서 별도로 입력할 역할, 리더여부, 기간 추가정보도 추가했다.
다음은 gpt에게 프롬프트를 요청하는 코드이다.
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
response_format={ "type": "json_object" },
#프로젝트의핵심기능, 소개(언어 및 프레임워크)
messages=request_messages,
temperature=1
)
API 통신을 위해 json 형식으로 response format을 받기로 하였고 속은 project_info, period, core_function 세가지가 포함된다.
Fast API
이제 마지막으로 이 서비스를 요청하는 API까지 구성해봤다.
요청받는 데이터의 종류는 다음과 같다.
class Request(BaseModel):
resposUrl: str #레포지토리 url
role: str # 역할 ex: 백엔드 등등
extra_info: str # 추가정보
leader: bool # 팀장 여부
그리고 API의 컨트롤러 부분이다.
@app.post("/gpt")
async def root(gpt_request: Request):
summarize_content = await gpt_summarize(gpt_request.resposUrl, gpt_request.role, gpt_request.extra_info, gpt_request.leader)
response = json.loads(summarize_content)
return response
최종 테스트 결과는 다음과 같다.
요청
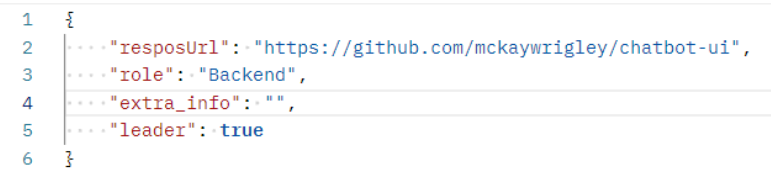
응답

'생성형 AI' 카테고리의 다른 글
| Gemini API, LLama API로 깃허브 리포지토리 요약하기 (0) | 2024.04.05 |
|---|---|
| ChatGPT API 사용해보기 (0) | 2024.03.31 |
| Github API 사용하기 (0) | 2024.03.31 |