
Intro.
지난 글에선 ChatGPT API를 통해 깃허브 리포지토리를 요약해보았다.
이번에는 Gemini API, LLama API를 사용해보겠다.
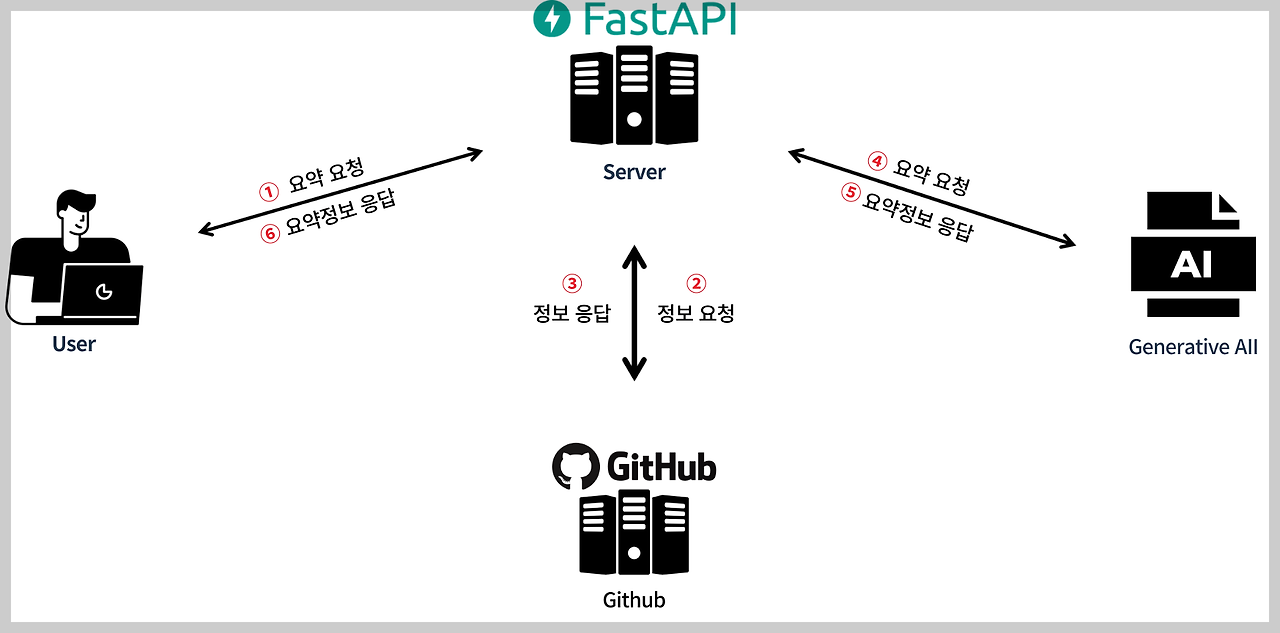
전체적인 구조는 이전의 ChatGPT를 사용할 때와 다르지 않다.
단지 LLM의 종류만 바꿨을 뿐이다.
Gemini API
Gemini API를 기본적으로 사용하는 방법도 ChatGPT와 크게 다르지 않았다.
API 키 가져오기 | Google AI for Developers
이 페이지는 Cloud Translation API를 통해 번역되었습니다. 의견 보내기 API 키 가져오기 컬렉션을 사용해 정리하기 내 환경설정을 기준으로 콘텐츠를 저장하고 분류하세요. API를 사용하려면 API 키가
ai.google.dev
해당 링크에서 API키를 발급받고 코드에 API 키를 넣은 뒤 코드를 작성하면 됐다.
Gemini 코드
from dotenv import load_dotenv
import os
import google.generativeai as genai
from read_repos import run
from calculate_bills import calculate
load_dotenv()
genai.configure(api_key=os.environ['GOOGLE_API_KEY'])
model = genai.GenerativeModel('gemini-pro')
async def gemini_summarize(repos_url, role, leader, extra_info=None):
result = await setParamter(repos_url)
directories = ','.join(result['directories'])
files = ','.join(result['files'])
readme = result['readme']
period = '20231123-20240215'
request_messages = f'''너는 프로젝트를 요약해주는 AI야.
요약 내용에는 세가지 정보가 포함돼.
1. project_info: 프로젝트 주제, 사용 언어및 프레임워크, 내가 맡은 역할
2. period: 프로젝트 기간
3. core_function: 프로젝트의 상세한 핵심기능(맡은 역할과 엮어서)
이 내용들은 이력서에 들어갈 것이야.
1번과 3번은 하나의 문장으로 주고 2번은 그냥 기간만
이 세가지의 정보를 json 형식으로 줘
디렉토리명은 {directories}
파일명은 {files}
readme는 {readme}
역할은 {role}
리더여부는 {str(leader)}
기간은 {period}
'''
if extra_info is not None:
request_messages += f"추가적인 정보는 {str(extra_info)}"
response = model.generate_content(request_messages)
return response.text
async def setParamter(repos_url):
parts = repos_url.split('/')
user_name = parts[3]
repo_name = parts[4]
result = await run(user_name, repo_name)
return result
# 테스트
# print(gemini_summarize('https://github.com/mckaywrigley/chatbot-ui', 'Backend', True))
전체적인 코드 구조는 ChatGPT와 동일하다.
그렇기에 Github Repository의 정보를 가져오는 부분에 대한 설명은 여기서는 생략하겠다.
프롬프트는 약간의 수정이 있었다.
request_messages = f'''너는 프로젝트를 요약해주는 AI야.
요약 내용에는 세가지 정보가 포함돼.
1. project_info: 프로젝트 주제, 사용 언어및 프레임워크, 내가 맡은 역할
2. period: 프로젝트 기간
3. core_function: 프로젝트의 상세한 핵심기능(맡은 역할과 엮어서)
이 내용들은 이력서에 들어갈 것이야.
1번과 3번은 하나의 문장으로 주고 2번은 그냥 기간만
이 세가지의 정보를 json 형식으로 줘
디렉토리명은 {directories}
파일명은 {files}
readme는 {readme}
역할은 {role}
리더여부는 {str(leader)}
기간은 {period}
'''
GPT에서는 응답을 json형식으로 받도록 지정할 수 있었지만 Gemini에서는 이러한 기능을 지원하지 않는 것 같았다.
(못 찾은 것일 수도 있다..)
그렇기에 프롬프트에 json형식으로 응답을 달라고 내용을 추가해줬다.
Fast API 라우터
@app.post("/gemini")
async def root(gemini_request: Request):
summarize_content = await gemini_summarize(gemini_request.resposUrl, gemini_request.role, gemini_request.extra_info, gemini_request.leader)
response = json.loads(summarize_content.replace('`', '').replace('json', ''))
return response
테스트
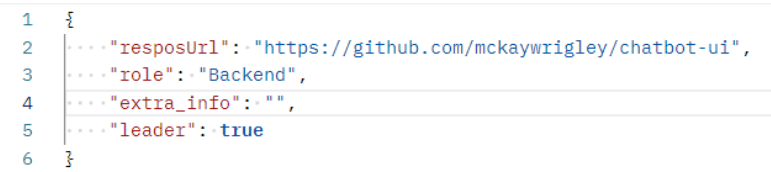

테스트 결과가 적당하게 나온걸 알 수 있다.
LLama API
LLama API를 사용하려면 해당 사이트에서 API Key를 발급 받아야 한다.
Obtaining an API Token - Llama API
docs.llama-api.com
LLama 코드
from llamaapi import LlamaAPI
from dotenv import load_dotenv
import os
from read_repos import run
import asyncio
load_dotenv()
llama = LlamaAPI(os.getenv('LLAMA_API_KEY'))
owner = 'mckaywrigley' # 깃허브 유저이름
repos = 'chatbot-ui' # 깃허브 레포지토리 이름
result = asyncio.run(run(owner, repos))
directories = ','.join(result['directories'])
files = ','.join(result['files'])
readme = result['readme']
async def llama_summarize(repos_url, role, leader, extra_info= None):
result = await setParamter(repos_url)
directories = ','.join(result['directories'])
files = ','.join(result['files'])
readme = result['readme']
period = '20231123-20240215'
request_messages = [
{"role": "system", "content": '''너는 프로젝트를 요약해주는 AI야.
요약 내용에는 두가지 정보가 포함돼.
1. project_info: 프로젝트 주제, 사용 언어및 프레임워크, 내가 맡은 역할
2. period: 프로젝트 기간
3. core_function: 프로젝트의 상세한 핵심기능(맡은 역할과 엮어서)
이 내용들은 이력서에 들어갈 것이야.
1번과 3번은 하나의 문장으로 주고 2번은 그냥 기간만'''},
{"role": "user", "content": "디렉토리명은 " + directories},
{"role": "user", "content": "파일명은 " + files},
{"role": "user", "content": "readme는 " + readme},
{"role": "user", "content": "역할은 " + role},
{"role": "user", "content": "리더여부는 " + str(leader)},
{"role": "user", "content": "기간은 " + period}
]
if extra_info is not None:
request_messages.append({"role": "user", "content": "추가적인 정보는 " + str(extra_info)})
# API Request JSON Cell
api_request_json = {
"model": "llama-13b-chat",
"messages": request_messages
}
response = llama.run(api_request_json)
return response.json()['choices'][0]['message']['content']
async def setParamter(repos_url):
parts = repos_url.split('/')
user_name = parts[3]
repo_name = parts[4]
result = await run(user_name, repo_name)
return result
Fast API 라우터
@app.post("/llama")
async def root(llama_request: Request):
summarize_content = await llama_summarize(llama_request.resposUrl, llama_request.role, llama_request.extra_info, llama_request.leader)
response = json.loads(summarize_content)
return response
테스트

뜬금없이 오류가 발생한 것을 알 수 있다.
원인을 알아본 결과 Input Context Window 수가 초과된 것이었다.

라마는 최대 4096개의 input 토큰을 지원한다.
리포지토리의 내용이 조금만 많아져도 오류가 발생한다.
GPT의 1/4 꼴인데 상당히 아쉬운편이다.
'생성형 AI' 카테고리의 다른 글
| Github Repository정보 ChatGpt API로 요약하기 (0) | 2024.04.04 |
|---|---|
| ChatGPT API 사용해보기 (0) | 2024.03.31 |
| Github API 사용하기 (0) | 2024.03.31 |