
1. 문제

프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
2. 풀이 과정
튜플을 표현한 집합이 주어졌을 때, 그 집합을 가지고 원래의 튜플을 유추하는 문제이다.
튜플은 순서가 다르면 다른 튜플이며
튜플을 표현한 집합 내의 원소는 순서가 상관이 없다.
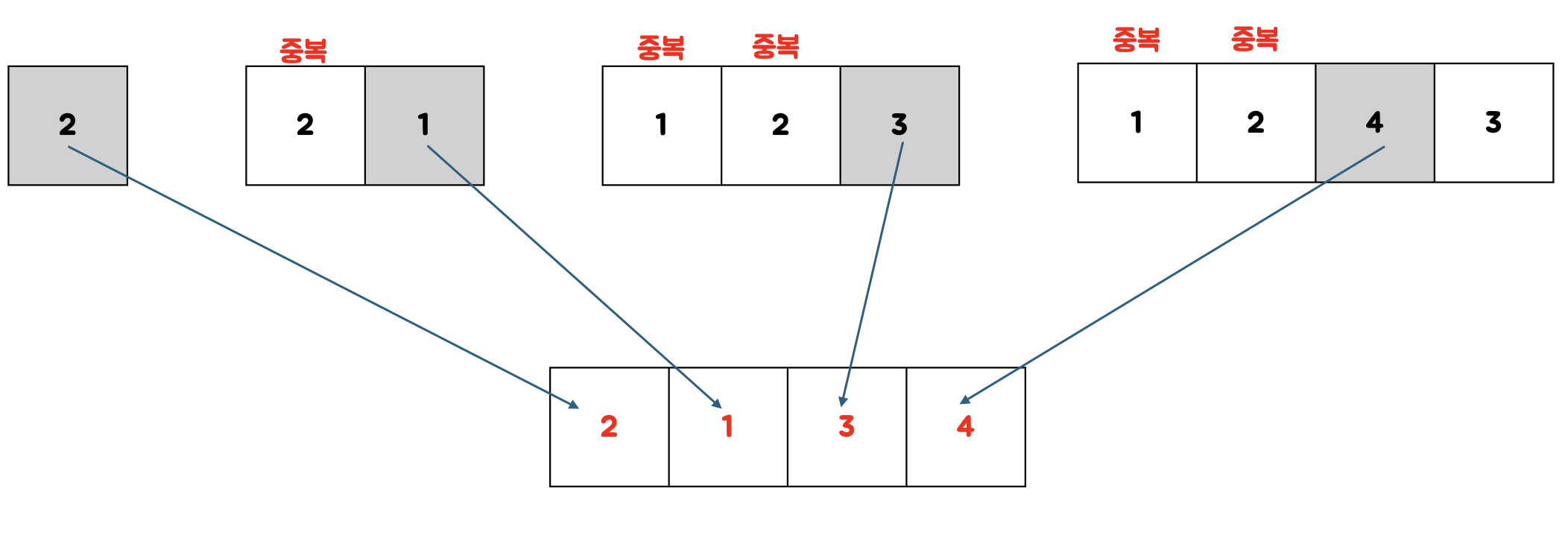
예를 들어 (2, 1, 4, 3)이라는 튜플이 있다면 이는
{{2}, {2, 1}, {2, 1, 4}, {2, 1, 4, 3}}으로 표현할 수 있는데
이 집합의 원소간의 순서도 상관없고 (예: {{2, 1, 3, 4}, {2}, {2, 1, 3}, {2, 1}})
원소 내의 순서도 상관이 없다.(예: {{1, 2, 3}, {2, 1}, {1, 2, 4, 3}, {2}})
그렇다면 이러한 규칙을 갖고 있는 집합을 통해 어떻게 원래의 튜플을 알아낼 수 있을까?
일단 집합의 원소내의 순서는 튜플에서의 순서를 보장하지 않는다.
하지만 확실한 것은 원소 내의 숫자 갯수가 1개면 그 수는 반드시 튜플의 맨 앞에 오게 된다.
이게 무슨말이냐면 {{1, 2, 3}, {2, 1}, {1, 2, 4, 3}, {2}}에서 {2}는 집합의 특성에 의해 반드시 튜플의 맨 앞에 오게 된다.
또한 튜플의 첫번째 수가 정해졌다면 튜플의 두번째수도 정해진다. 바로 숫자 갯수가 2개인 튜플을 보면된다.
위의 예시에선 {2, 1}인데 여기서 2는 이미 튜플의 첫번째 수이므로 1이 두번째 수가 된다.
이걸 반복하게 되면 최종적인 튜플을 알아낼 수 있다.
따라서 이 문제를 해결하는 과정을 정리하면 다음과 같다.

1. 원소의 갯수를 기준으로 오름차순 정렬한다.

2. 원소의 갯수가 작은 순서대로 튜플의 숫자를 하나씩 추가한다.
3. 내 코드
import java.util.*;
class Solution {
public int[] solution(String s) {
// 각 원소를 배열에 저장
String[] tuple = s.substring(2, s.length() - 2).split("\\},\\{");
// 숫자의 갯수(길이)를 기준으로 오름차순 정렬
Arrays.sort(tuple, (s1, s2) -> s1.length() - s2.length());
// 숫자의 갯수가 작은 원소부터 값을 하나씩 저장
Set<Integer> set = new HashSet<>();
int[] answer = new int[tuple.length];
for(int i = 0; i < tuple.length; i++) {
String[] atoms = tuple[i].split(",");
for(String a: atoms) {
int atom = Integer.parseInt(a);
// 중복되면 저장 X
if(!set.contains(atom)){
set.add(atom);
answer[i] = atom;
break;
}
}
}
return answer;
}
}시간 복잡도
- O(N)
s를 문자열 배열로 변환: O(N) (N: s의 길이)
문자열 배열을 정렬: O(KlogK)
숫자의 갯수가 작은 원소부터 값을 하나씩 저장: O(K^2) (K: 문자열 배열의 크기)
이때 N이 최대 100만이고 K가 최대 500이라고 했으므로 실질적으로는 O(N)이다.
주의할 점
// 각 원소를 배열에 저장
String[] tuple = s.substring(2, s.length() - 2).split("\\},\\{");해당 부분을 보면 split()을 할 때 이스케이프 문자('\\')를 이용하였는데 그 이유는 '{'와 '}'를 동시에 사용하면 정규 표현식 엔진은 이를 반복 횟수 지정자로 해석하려고 시도하기 때문이다. 따라서 반드시 이스케이스 문자를 사용해야 한다.
기억해두기
// 숫자의 갯수가 작은 원소부터 값을 하나씩 저장
Set<Integer> set = new HashSet<>();
int[] answer = new int[tuple.length];해당 부분에서 중복을 체크하기 위해 해시셋을 사용했다.
물론 리스트를 사용하면 중복체크와 정답을 하나의 자료구조에 넣을 수 있었겠지만 굳이 두 개를 사용하면서 까지 해시셋을 사용한 이유는 해시셋의 특성 때문이다.
if(!set.contains(atom)해시 셋에선 특정 데이터가 포함되있는지를 알려주는 contains()메서드를 O(1)의 시간복잡도로 해결한다.
반면 리스트의 contains() 메서드는 모든 데이터를 순회하며 해당 데이터가 포함되어있는지를 체크하기 때문에 O(N)이다.
따라서 중복체크를 할 때 해시셋을 사용하면 효율을 증가시킬 수 있다.
'코딩 테스트 > 프로그래머스' 카테고리의 다른 글
| [프로그래머스] 전화번호 목록 (0) | 2024.06.21 |
|---|---|
| [프로그래머스] 지형 이동 (0) | 2024.06.21 |
| [프로그래머스] 가장 큰 수 (0) | 2024.06.20 |
| [프로그래머스] K번째 수 (0) | 2024.06.20 |
| [프로그래머스] 정수 내림차순으로 배치하기 (0) | 2024.06.20 |